Wprowadzone niedawno na rynek procesory Intel 4th Gen Xeon “Sapphire Rapids” odnotowały przyspieszoną adopcję w segmencie chmury i centrów danych. Jednym z kluczowych obszarów, w którym Intel włożył dodatkowy wysiłek, jest ich zestaw funkcji sprzętowych do akceleracji głębokiego uczenia się, który jest zwiększony dzięki nowym akceleratorom AMX (Advanced Matrix Extension).
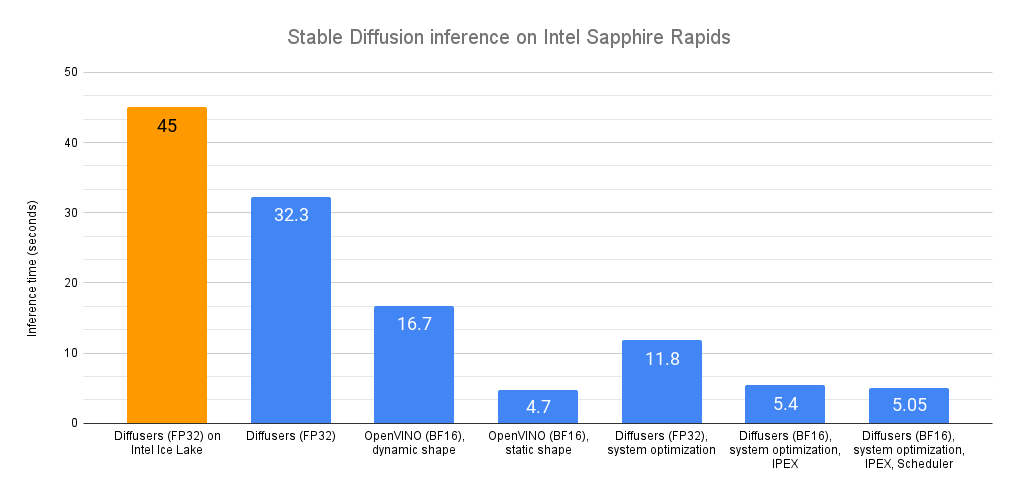
Intel najpierw pokazuje średnie opóźnienie między obecną generacją Sapphire Rapids i ostatnią generacją procesorów Ice Lake. Procesory Xeon trzeciej generacji potrzebują około 45 sekund na uruchomienie kodu, podczas gdy procesory czwartej generacji 32,3 sekundy. To o 28% niższa latencja bez żadnych zmian w kodzie. Co więc, jeśli Intel miałby użyć zoptymalizowanego i otwartego zestawu narzędzi do wnioskowania o wysokiej wydajności, jak OpenVINO?
Odpowiedzią jest jeszcze większy wzrost wydajności! Dzięki Optimum Intel i OpenVino, procesory Intel Xeon obniżają opóźnienie do 16,7 sekundy, co daje ponad dwukrotny wzrost prędkości. Dalsza optymalizacja kodu do stałej rozdzielczości obniża opóźnienie do zaledwie 4,7 sekundy, co oznacza 3,5-3,8-krotny wzrost wydajności w stosunku do nietkniętego kodu.
Przy statycznym kształcie, średnie opóźnienie zostaje skrócone do 4,7 sekundy, co oznacza dodatkowe 3,5x przyspieszenie.
Jak widać, OpenVINO to prosty i wydajny sposób na przyspieszenie wnioskowania metodą stabilnej dyfuzji. W połączeniu z procesorem Sapphire Rapids, zapewnia on niemal 10-krotny wzrost prędkości w porównaniu do wnioskowania waniliowego na Xeonach Ice Lake.
Jeśli nie możesz lub nie chcesz używać OpenVINO, reszta tego postu pokaże Ci szereg innych technik optymalizacji. Zapnij pasy!
Włączamy także format danych bloat16, by wykorzystać akcelerator AMX tile matrix multiply unit (TMMU) obecny w procesorach Sapphire Rapids.
W tej zaktualizowanej wersji opóźnienie wnioskowania zostało jeszcze bardziej zredukowane z 11,9 sekundy do 5,4 sekundy. To ponad dwukrotne przyspieszenie dzięki IPEX i AMX.
W tej ostatecznej wersji opóźnienie wnioskowania spadło do 5,05 sekundy. W porównaniu z naszym początkowym benchmarkiem Sapphire Rapids (32,3 sekundy), jest to prawie 6,5x szybciej!
Intel
Dalsze optymalizacje na poziomie systemu, IPEX i BF16 przynoszą jeszcze większą wydajność, a wyniki można zobaczyć na ładnym wykresie dostarczonym przez samego Intela:
Intel’s Sapphire Rapids Xeon CPUs są obecnie dostępne do podglądu na instancjach Amazon EC2 R7iz, możecie się tu sami zarejestrować, aby uzyskać dostęp i zobaczyć zalety, które rodzina procesorów 4th Gen wprowadza. Wraz z rosnącą popularnością Stable Diffusion i podobnych modeli AI, widać dlaczego procesory Intela staną się popularnym wyborem w tym segmencie.